
In two recent articles we proposed a solution to create a decentralized financial computing system to serve Web 3.0 which can be extended to the different blockchain designs, and published why we feel the modular blockchain design best addresses the Trilemma problem (i.e., scalability, decentralization and security). In this article, we present our ideals into one desirable blockchain that presents the most efficient way to achieve decentralized scalable consensus to serve a smart contract platform.
Table Of Contents
· Verify-then-trust everything
∘ EIP 1559
∘ Minimum Viable Inflation
∘ Proof-of-service
· Merged-mining Bitcoin for shared green security
· MEV protection
· Scaling & Privacy through modular blockchain design
∘ Offchain data availability security
∘ Systemic alignment of economic activity on layer 1
Verify-then-trust everything
The devil is in the details when comparing differing designs for layer 1 (L1) blockchains. On one hand you have Bitcoin, which uses a tried and tested decentralized model where every node checks everything and makes no tradeoffs of subset of nodes participating in special consensus. However, on the other hand you have chains with subsets of nodes acting under authorization which is kept honest by crypto-economics to honestly validate and provide optimizations to base layer performance.
We argue that it is possible to scale and provide light-client security effectively for a smart chain with consensus across every node. This can be achieved by: (a) incentivize full-nodes, achieve “ZK-SNARK everything”; (b) align L1 economic incentives for finance using zero-knowledge proof (ZKP) systems such as ZK-Rollups instead of using L1; and © and find ways to scale on data availability serving rollups without introducing shared costs to create a minimal viable consensus for a blockchain system that retains the trust and security model of Bitcoin but scales as a modular blockchain.
With the development of zero-knowledge proofs, we have been able to see how we can optimize and increase performance in ways which do not require us to make these tradeoffs from the complete decentralized model of verify-then-trust everything. Blockchains are responsible for two things to ensure security of funds, Computational consensus and data availability. Computational consensus ensures the ledger is in a consistent state by assuring any local node can recompute the balances of everyone to ensure no double-spends have occurred, and data availability ensures you have the information needed to move funds on the blockchain. Since computational consensus can be replaced by ZKPs, we can focus on data availability as the next direction of research to create decentralized systems without the need to depend on supernodes or subsets. That is not to say a subset of nodes cannot be useful (i,e,: for proof-of-service — see below). Bitcoin assumes at least 1 other node is available for synchronization so that locally one can assure they are not only in the correct state, but also can communicate with the network safely. If connectivity between nodes is established and they are all honest participants, then you have an altruistic model for participating in consensus (i.e., Bitcoin) that is fully decentralized and no third-party dependence on security other than yourself. Deviating away from this design could and will lead to disastrous consequences as it is placing trust, security and authorization of the network away from the model that has proven to work (i.e., miners competing to form blocks and with full nodes either accepting or rejecting them) to something with untold vectors of gamification to create advantages to specific participants.
We would like to design systems that do not trade fundamental tenets of the design of chain which is the most decentralized, meaning every node checks everything and a miner mechanism design which is working under a game theory model expending real world resources as a base cost to create a value of work represented in the form of blocks, paid by fees and block subsidy.
The premise in this article is that any base layer blockchain design that deviates from these tenets will result in a degradation of security or the economic hardness of the asset, resulting in less decentralization and attack vectors resulting from black swan events. Although it may seem possible to do light-client or embedded devices that can efficiently synchronize to systems with Proof of Stake (PoS) and sharding designs, this results in a system more susceptible to the long-term effects of economic game-theory malfeasance. The result of such decisions could lead to a continuous set of hard forks to exit out of check-mate scenarios which will end up leading to a crisis of confidence in such systems.
Regarding light-clients, it is important to note that users do not need to download a full base-layer to have trust-less interaction with the modular design as they would likely be sitting on a layer 2 (L2) ZK-Rollup. This is where a simple merkle proof can prove a user’s balance with a ZKP verification guaranteeing the latest state of the rollup; responding within milliseconds and under 100kb of bandwidth requirements.
EIP 1559
EIP-1559 is a promising way forward to create long-term economic benefits to a blockchain design geared towards serving utility through a Turing-complete economy of contracts.This allows us to achieve an efficient way to secure our ledger while remaining eco-friendly by utilizing PoW from Bitcoin miners in a merged-mining mechanism.This also provides incentives for full-nodes to run long-term without the concern of relying on fees to remain profitable. By relying on PoW in a verify-then-trust decentralized network, we create economic hardness of coins to a greater degree than those of other forms of consensus because there is provable energy expended in the creation of the coins. We couple that with a validator strategy where the validators are essentially paid to run full-nodes. EIP-1559 enables all of this as a way to decouple deflation risks and manage them in a very efficient way. This is done by assigning a minimum inflation strategy to keep the network healthy and keep participants who are assigned to do work profitable long-term.
Minimum Viable Inflation
Every L1 chain needs to defend itself with a cost model in the form of a gas token which competes for block space and execution, as well as data availability to serve modular architecture (see below for more on that — Proof of Data Availability or PoDA). In order to pay for this defense, the consensus needs to:
1) Inflate money supply
2) Tax block space usage
3) Tax data availability assurances (again more on this below — PoDA)
If inflation costs exceed tax revenue then one is operating at a deficit. A deficit is not sustainable long-term. Either the token’s value would need to appreciate, or available block space would need to be restricted to achieve equilibrium/surplus in security. A sustainable L1 would make the block space and data availability assurance valuable. Making block space valuable would require demand for L1 block space which comes in the way of rollups and validity proofs as well as the odd executions from users on L1. Data availability assurances would come in the way of rollups requiring guarantees of data replication for volition models to scale up the ZK-Rollup paradigm. This should remove the cost bottleneck of onchain data availability for rollups to the computing cost of creating the ZKP which would lead to a decentralized cost model.
It is important to determine the minimum viable amount of inflation necessary to create a long-term sustainable platform. If we compare the extreme’s where we deflate to 0 and inflation becomes nothing, the cost of the token could end up prohibitively high creating an undesirable economy to use block space and availability. If we inflate too much, then we start operating in a deficit and security ends up suffering long-term.
In Syscoin we modelled out inflation based on natural growth of population to match long-term growth of demand in an ideal blockchain system where financial computing is used as a base-layer to power smart cities, IoT, DeFi, metaverse and all sorts of decentralized application paradigms.
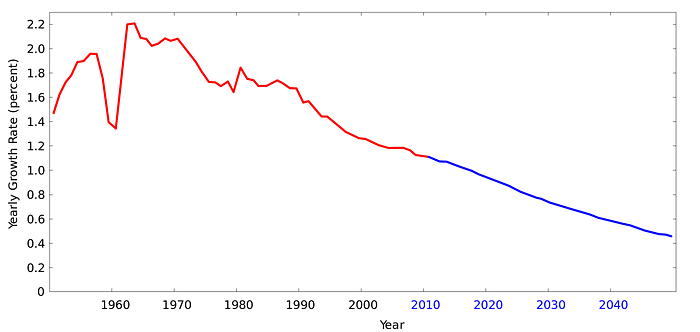
As you can see we are at about a 1 percentage growth trajectory falling over time which is the same rate of emissions we have with Syscoin. In the event of full adoption, we anticipate demand for using the system will perpetually grow along with the population. However, this does not account for AI users and we believe they will find more optimal usages of L1 real-estate by relying on L2 and only invoking L1 when necessary.
By giving a long-term inflation strategy, which is the minimum amount based on growth of population, we can achieve long-term equilibrium on the security defense of our ideal blockchain design. Paid full nodes (i.e., masternodes) and miners should be given long-term assurances of block subsidy. In a merged-mine model, Bitcoin miners may leverage this assurance, as Bitcoin subsidy deflates towards being negligible.
Proof-of-service
Since we verify and trust everything, we don’t have a consensus system that depends on a subset of nodes to provide the ultimate trust model in our ideal blockchain design. However with decentralization, we anticipate to still have a profit model to help incentivize long-term nodes to run and keep the network sybil-resistant. The creation of a Proof-of-Service module serves as a foundation to build other required features in our ideal design such as Miner Extractable Value (MEV) protection and finality but also specifically for the service that creates a base-layer of liveness to be able to connect to an honest full node at any time. This is in contrast to altruistic assumptions like in Bitcoin and other decentralized networks where at least 1 connecting node is assumed to be honest. However, if one does not rely on staking validators to create Proof-of-Service, the question remains how this gets achieved.
With Syscoin, masternodes are used which require 100,000 SYS as locked collateral. The masternode works by confirming a transaction on the network, and through a quorum mechanism there is an aggregate Boneh-Lynn-Shacham (BLS) signature formed to assure liveness through a Distributed Key Generation (DKG) process. If during the DKG process certain registered nodes do not respond with valid signatures, they are marked bad as they are not providing liveness and are rejected from participating as masternodes, and lose future block subsidies until they re-establish liveness. Instead of negative or punitive economic alignment with these special nodes (which we do not feel is safe and desired by network participants) we instead let the network reserve the right to stop the masternode from participating which requires re-registration and waiting for another round to be paid. Quorums are established every 12 hours, hence masternodes not providing service will be caught during the DKG process.
Once we have a set of masternodes, we create a base-level of network liveness which creates assurances of honest network policy being enforced, making it much harder for miners to disseminate bad information.
Merged-mining Bitcoin for shared green security
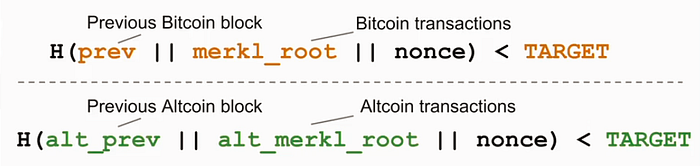
Fig. 2 presents the basic idea of merged-mining with Bitcoin. The nonce is mined by Bitcoin miners and creates a block on the child chain (Syscoin in this case) solved under its difficulty target, but not necessarily solved on the parent chain (Bitcoin). Keep in mind that this rudimentary presentation of merged-mining considers other things which go beyond the scope of this discussion. However, one can see that the child chain does not need to verify the Bitcoin blockchain (adhere to its policy), but can form its own rules.
However, naive merged-mining also has its problems, as Luke Dash Jr. demonstrated through a CoiledCoin attack in 2012. Therefore, selfish-mining strategies are needed so that a pool with majority hash can not reject the work of the minority part of the network, toward negating the attack’s usefulness. Hence, transaction finality is required. Syscoin solved this issue via chainlocks, but any sort of supermajority voting consensus via validators done in a secure way can solve this. However, it’s worth noting that if the validators are not bonded by hard money (i.e., expended resources) then it is not a secure strategy. This can be witnessed during black-swan events when there are windows of opportunity to game the finality to one’s benefit by disrupting validators that are responsible for the selfish-mining solution on a chain.
MEV protection
When introducing Turing-completeness and ultimately Decentralized Finance (DeFi), there are externalities for revenue opportunities created that don’t exist in the Bitcoin model. For example, miners can be bribed to re-organize a blockchain if there is an out-of-band trade available in the DeFi ecosystem that will pay more than the cost of re-organizing the chain, which affects honest users in that they can potentially have their transactions reverted. This is called MEV (miner extractable value) and is a result of enabling DeFi or out-of-band economics in an environment where authorizing participants in consensus can be coordinated by tips, bribes, or generally form some sort of collusion. The complexities of MEV on the base layer are almost impossible to avoid in a DeFi settlement layer, since even with privacy there may always be ways to detect economic anomalies to have miners participate in auctions to re-organize blocks. The only way to solve this problem is to impose finality on the chain in order to remove longer-term MEV attacks by capping the term of the attack for a DeFi settlement layer. For instance, with Syscoin instead of trading-off the Bitcoin model, we wish to create a probability model that considers the honest majority of masternodes to invoke chainlocks. Doing this awards some authorization on the part of an honest majority of supernodes in a way where if there is collusion and consensus that cannot be formed, then a traditional Bitcoin consensus model is invoked. If there is any chance that masternodes find a way to collude (through a super majority of nodes) then blocks must semantically still be correct, hence proving they did the right amount of work according to the current difficulty.
Scaling & Privacy through modular blockchain design
In our previous article, we established the importance of designing a good L1 strategy. We argued that modular blockchain design not only allows for computational and data availability scale, but also privacy aspects that are inherited from ZKP systems.
Offchain data availability security — introducing PoDA
Here, we highlight a common attack against a volition based ZK-Rollup. The sequencer and offchain nodes that run consensus on the data stored offchain (i.e.,data availability) collude and do not actually store the data, or they manipulate the data slightly such that the stored data does not accurately represent the real account state stored on chain. When the time arrives to exit back to L1, users do not have the ability to get the information required to prove they are part of that account state because the data was manipulated under collusion. Therefore, the security guarantees of rollups which store data offchain cannot be the same as L1.
Towards solving this, let’s break-down data availability into two parts. The first part is proof of replication and the second is archiving. We will call this Proof-Of-Data Availability (PoDA).
Replication typically requires some sort of consensus, which is the concept behind Celestia and Polygon Avail. These systems also archive the data and use different mechanisms to provide the likelihood of data availability. Despite the novelty of these projects, recently researchers found that we cannot depend on external consensus systems without compromising L1 security. This is not favorable when designing rollups with the desired L1 level security.
In contrast, archiving has a space complexity of O(1) to be censorship resistant, if that participant allows others to download it to present their proofs to be able to exit. This results in a much safer design than the alternatives. Users can store their own data or use services. This can create great assurances that data is available and do so without introducing all the shared cost of storing it on L1. A potential attacker would be unable to force all copies in the world into unavailability, as they lack the control needed to force such a scenario.
Data availability in any distributed system is really a Big Data problem. To address a Big Data problem in distributed systems we need to analyze shared costs.
In Ethereum the design is to expand data availability through sharding with a recent proposal to create a monolithic data availability solution using KZG commitments created by block producers. These are breakthroughs in creating data availability using L1 security to serve rollups however at the cost of reduced decentralization and systemic security. In any examples that break the tenets outlaid in this article we hypothesized that reduced security would result. In cases like this, if consensus were to collude or break to allow for sharded data to represent a valid KZG commitment to ZK-Rollup state differential data but its modified by the sequencer to create censorship, since the ZK-Rollup is final as soon as the state transition is done, this creates a situation where the ZK-Rollup essentially locks all users balances without the ability to withdraw back to L1. In our ideal design we would use full decentralized security to check for PoDA but not use shared resources to archive the data which does not require consensus. This reduces shared costs, separates concerns for who should archive the data and provides full systemic decentralized security on the data integrity.
PoDA efficiently arms the network with censorship resistance of ZK-Rollups for offchain or validium based accounts which completes the picture to enable massive scale without affecting the decentralized aspects of local verification with the same honest peer assumption as bitcoin itself. The execution scalability is achieved by ZK-Rollups and Big Data scale of offchain data availability is achieved by a proof-of-replication concept where we only need to store ZK-Rollup calldata for a short period of time safely removing it under the assumption that at least one honest peer in the network will archive it. Today, ZK-Rollup solutions typically deal in a two-stage process to transition state on L1. In the first stage, sequencers would provide validity proofs of the correctness of the execution into the L1 smart contract. The sequencer would subsequently present to the Syscoin network, the calldata and hash of calldata where network participants confirm the correctness providing an OPCODE in the EVM to store the fact that the correct calldata is stored network wide temporarily for data availability purposes. In the second stage of the ZK-Rollup state transition, the sequencer calls the verifying contract again and the contract reads the OPCODE to enforce network validation of data liveness and correctness. Please note that the verifier must also take in the hash as the public input to the proof verification to ensure the calldata stored network wide temporarily is committed to by the zero-knowledge proof.
If we used data shards in a shared cost model, the cost of throughput of 4 million TPS (assuming ASIC provers for SNARKs/STARKs exist) @ 20 bytes each transaction will require over 2.5 petabytes of storage per year which will add tremendous cost translated to the user and systemic strains especially in assuring that data exists and is retrievable. Also the storage of data from different rollups will be likely disproportionate in that some will require more storage than others yet secured under the same conditions and same sharded infrastructure. It would be ideal if participants in each rollup archived their own offchain data if and only if there are assurances to the data’s replicability .
Let’s assume there are two rollups, where one is operating at 1 TPS while the other is at 3,999,999 TPS. In this scenario, the cost will be shared and the rollup doing 1 TPS will be much higher than it should be due to the load distribution with the other rollup doing 3,999,999 TPS.
In a properly configured system, the base-line cost to the network will only be to produce a replication proof (i.e., storing the offchain diff temporarily for a few hours). The base-line storage cost will be specifically for each rollup and so the rollup with 3,999,999 TPS will cost substantially more than the one with 1 TPS due to higher hardware requirements offloaded to the users. When we say base-line this means a minimum cost model: Profitability of the rollup systems would factor in minimum computational overhead costs for revenue as profit (i.e., cost to participate in consensus). The 1 TPS rollup will be much less as the cost to participate in consensus is substantially less as well as the archiving costs.
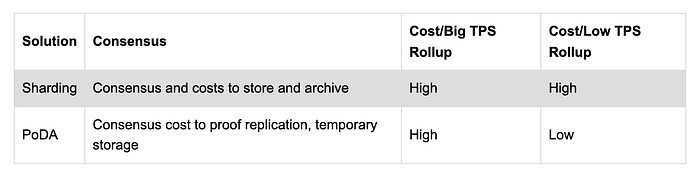
With PoDA there are lower shared costs for rollups with less throughput than others for the reason that archiving is separated from L1 consensus.

When diving further into the features, typically data replication requires an Honest Minority Assumption (in our design we have the entire network validate it for security purposes) whereas smart contract execution requires Honest Majority Assumption. However, by separating archiving of data, we do not need consensus nor spam protection, therefore the cost model is much lower long term, which becomes exasperated with higher throughput system-wide as shared resources are stressed.
Examples of data replication include Celestia, and Avail by Polygon which bundle both replication proofs and archiving. Since these systems are required for replication proofs, consensus and spam resistance needs to be built-in. Hence, the security of a rollup, depending on these systems for data availability, cannot be the same as L1. Hence, depending on external consensus for critical security components, this will cause auxiliary censorship risk for L2 rollups. Today, zkSync Guardians use majority assumption to secure L2 blocks by storing data and replication proof through a majority consensus Hence, paying out token rewards to guardians in exchange for their work.
Let’s circle back to the collusion scenario that causes an attack on existing ZK-Rollup volition designs with PoDA enabled. Here, there is no way to present a state transition with incorrect data, as it only takes one honest entity to store and present this data to achieve censorship resistance. Businesses that run as a service can store this data on behalf of users or archive the rollup data they are involved in themselves. Even onchain contracts can provide data upon demand through SNARK based private data exchanges.
Well-designed rollups can be developed without the need of special tokens utilizing the base chain token for gas costs pertaining to data availability on L1. Hence creating value uniformly, without introducing unnecessary complexity with additional tokens, which may or may not retain value and affect data availability security assumptions like some of the ones we currently see on Ethereum. Since only one honest node is required to store the data, these services can be offered by anyone including data-as-a-service offerings which store and make cloud based redundancy solutions for a fee available to users. Users are free to also use the tooling to store their own if it’s their choosing. By removing separate token requirements, we also remove the need to whitelist and do governance of the rollups. Thus achieving better decentralized attributes while enabling true permission-free L2 solutions.
Systemic alignment of economic activity on layer 1
The last piece of the puzzle is to create economic alignment to ensure that those using rollups on the base layer should either: (a) use it by paying more; or (b) create incentives for sought after real-estate on the chain. Blocks can dynamically expand as parallelization is used in rollups, but rollup sequencers (and thus users) will not need to compete with regular DeFi on L1, saving us from an inefficient fee market. To achieve proper decentralization with the highest possible security, we do not break any fundamental design principles (laid out in this article) but instead implement the best components suited for scalability and global competitiveness
With Syscoin, we achieve this with an extended block time (for inconveniencing users from using the base layer for activities) to stabilize finality using PoW, without requiring a hard finality guarantee, which can break the system as described earlier in this article.
Users also have the option to store their data within the execution engine as well, which guarantees not only replication, but storage at a higher cost (since it is stored in shared storage for the duration of the chain). This rightfully creates a cost tradeoff, while offering the highest possible security of offchain data policy for ZK-Rollups via either onchain storage or that a single honest peer archived the data.
If collusion is not possible in this design, then the costs will better reflect the cheapest possible logical path to execute and archive data on or off the chain.
By aligning incentives, the rollup sequencers would not have to compete with users doing DeFi and other operations on the primary layer, but on secondary layers. Doing This would create the most efficient use of the blockchain and optimally reduce costs. Yet, at the same time retaining its decentralization and security of the L1 in a verify-then-trust model. There would be less constraints for resources network-wide as demand for block space would be mostly rollups along with a small number of transactions from users and institutions. Therefore, block space itself does not need to expand exponentially to serve data availability and archiving. Finally, there is a separation of concerns since higher amounts of data availability are needed with L1 security. In this separated paradigm, we rely on PoDA to serve us our data needs as rollups scale up in throughput and rely on separate archiving policies based on individual or rollup based preferences. At Syscoin, we believe this is the state-of-the-art blockchain design that will be used to onboard a methodologically engineered decentralized Web 3.0 platform that will scale globally for the long term.
Thanks to Frank Lenniger (Blockchain Foundry), Bradley Stephenson (Syscoin Foundation), Dr. Ian Moore (Syscoin Foundation) for their contributions and review.